让社交媒体成为你的RAG应用输入
Why I did this?
作为一个从十岁就开始拥有自己QQ帐号的高强度网络冲浪90后选手。从大概五年前就开始思考,收集整合我的所有social media发言内容可以做点什么,那时候开了一个空的Github 项目,但也没作成什么实际的内容 https://github.com/SallyKAN/social_media_backup
信息时代里,数据是新的石油这句话对个人用户来说好像并不示用,因为个人很难拿自己创造的数据做点有意思的事,而big tech却可以靠你的个人数据日进斗金,他们分析你的用户画像,推荐定义你应该会喜欢的事物,依靠你的数据获取你的注意力。那些我们想删去的,过时的,愚蠢的社交媒体发言反而成为了汝之蜜糖彼之砒霜。
五年前我能想到最直接的应用就是通过爬虫把所有个人的社交媒体内容爬取下来,然后搭一个类似搜索引擎的social media brain,但是数据是我本地私有的,如果我可以发现一些有趣的内容或者insight,可以选择公开。甚至到后来,我可以有一个庞大的只属于我自己回忆的语料库,当然前提是你曾经是一个真正喜欢在社交媒体上暴露自己,发表观点,生活感悟的人。对于那些出生比我更晚,更小就拥有社交媒体,更加有表达欲的年轻一代们来说,活在社交媒体上,似乎也已经快成为现实。
那么接下来可以拿我们愚蠢的发言做什么?
一直到2023年chatGPT的出现,顺带孕育而出RAG应用,我突然发现也许有一种更偷懒的实现,也就是将自己社交媒体的内容作为RAG应用的输入。
What is RAG + LLM
LLM, Large Language Model 本质上有点像对互联网的压缩,因为如果你能非常准确地预测下一个词,你可以用它来压缩数据集,所以它只是一个下一个词预测的神经网络,你给它一些词,它会给你下一个词。而实现这种预测的核心就在于每个LLM模型的参数,以开源的Llama 2模型为例,这个系列有多个模型,对应不同的参数规模,7 亿、13 亿、34 亿。模型的训练过程是为了获取这些参数,而模型的运行过程可以称为模型推理,有了开源LLM,我们可以直接在本地运行模型。
在这里我们不关心模型训练,因为那是成本极其昂贵的复杂过程。我们只关心如何运行一个已经训练好的模型,根据提示去获取我们想要的结果。但我们很快就会遇到一个问题,即模型训练数据是静态的,并引入了其所掌握知识的截止日期,我们只能获取模型训练之前的信息。
RAG就是为了给LLM模型外挂一个实时的知识库,它会重定向 LLM,从权威的、预先确定的知识来源中检索相关信息。
一个RAG 与 LLM 配合使用的概念流程
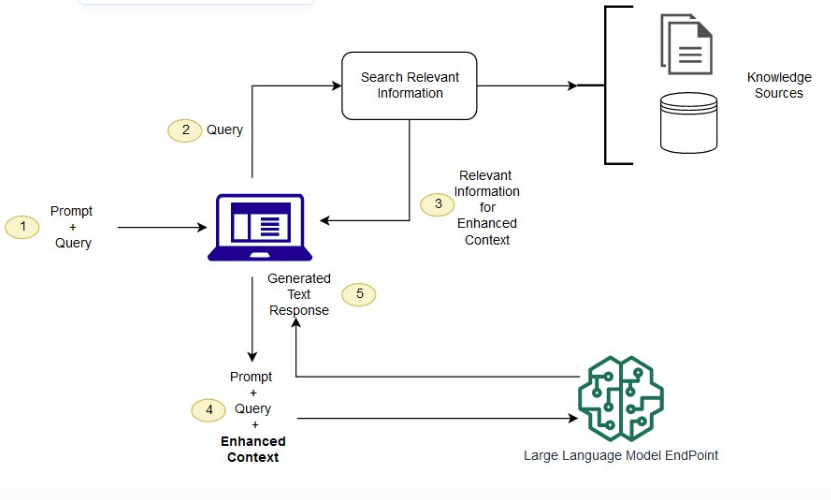 简单来说我们可以外挂我们自己的社交媒体内容,通过RAG(检索增强)的方式投喂给LLM模型,获取一些好玩的回答和响应。
简单来说我们可以外挂我们自己的社交媒体内容,通过RAG(检索增强)的方式投喂给LLM模型,获取一些好玩的回答和响应。
How to do it
如何开始实现这一个idea呢?先从一个简单的提问chatGPT开始
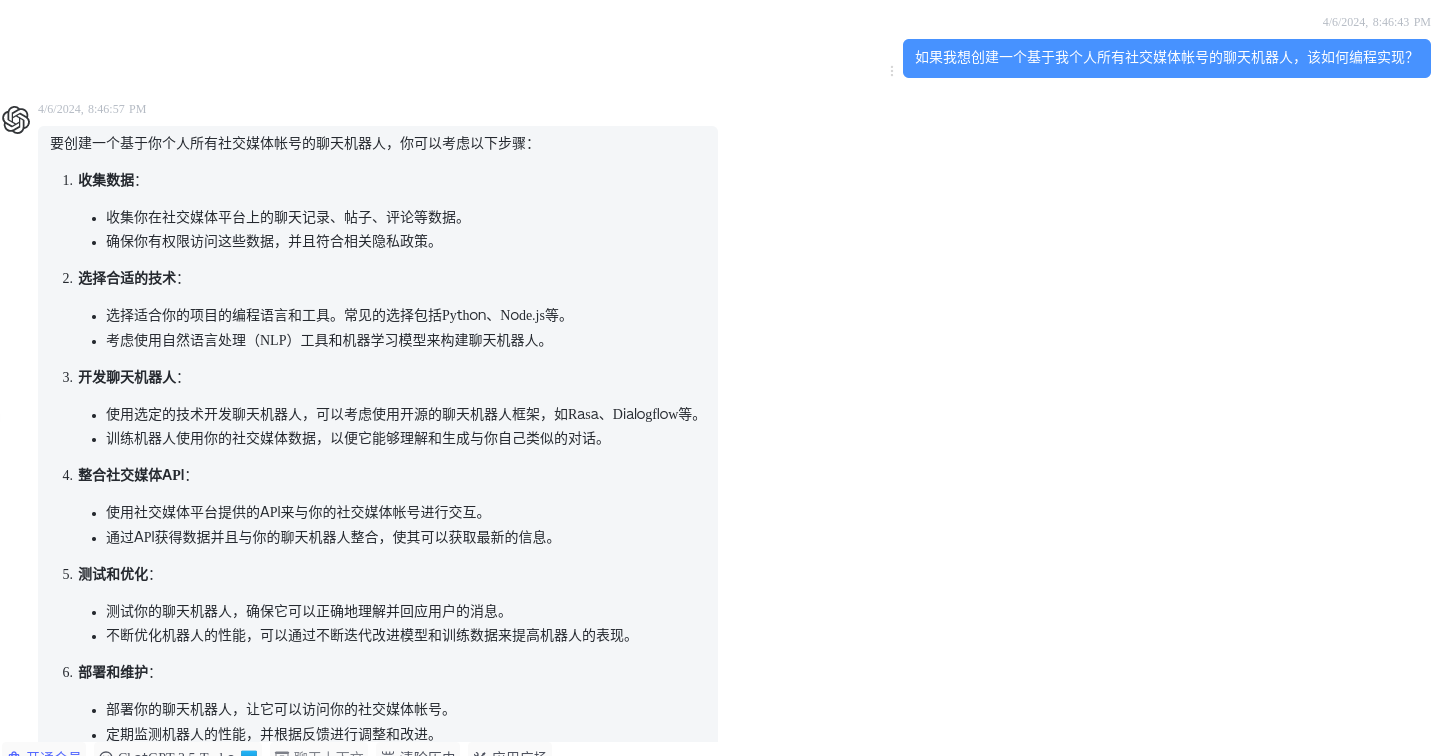
那么基于这几步我们就可以开始进行技术调研
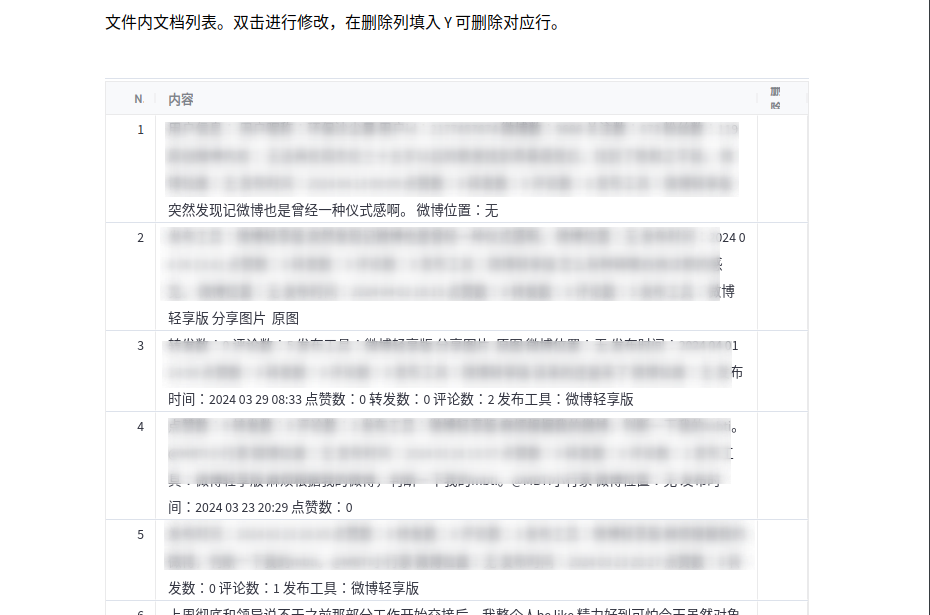
收集数据
以微博数据为例,我们首先需要一个爬虫工具。Github上有很多这样的开源工具,比如这个https://github.com/dataabc/weiboSpider ,有几点需要注意:
-
因为是爬取自己的微博内容,所以应该参考这个issue,
-
我们只需要微博内容,其他的信息不需要,所以最好修改爬取存取的内容

运行成功后,我们保存爬取的微博内容为.txt文件,作为后续的RAG知识库。
LLM应用开发的框架
直接选择langchian, 可以使用很多开箱即用的调用大模型的能力。参考官方示例:https://python.langchain.com/v0.2/docs/tutorials/rag/
但问题在于langchain的官方demo使用的都是英文大模型,我们爬取的微博内容都是中文,这时候我们应该需要一个更适配中文大模型的开发框架,也就是我们需要
- 一个微调的中文大模型
- 支持RAG的解决方案
- 可以开箱即用的chatbot UI和界面访问能力
调研下来也就是Langchain-Chatchat 解决的痛点:
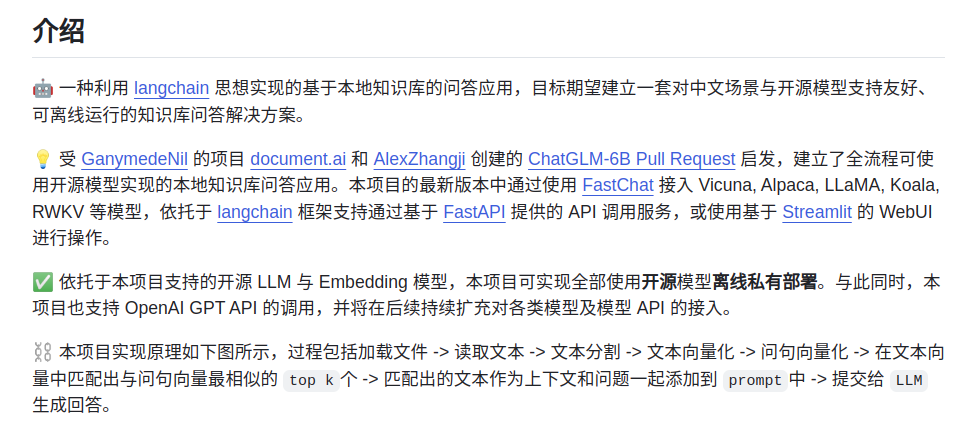
中文大模型
实测了一把chatGLM和LLAMA-2-Chinese,最终还是选择了ChatGLM
本地运行的硬件要求
虽然前文提到,运行模型已经是相对成本低廉的,我们可以从HuggingFace上下载ChatGLB模型 , 但很快我发现即便是号称性能与资源已经最好平衡的Llama 3, 也仍然需要至少8GB显存的Nvidia GPU,才能满足模型推理性能。
我的个人开发笔记本别说有Nvidia GPU, 甚至连独立显卡都没有,都是集成显卡。
显然我们需要更加一个云端部署的,便宜的的解决方案,一番调研后我选择了AutoDL
关于Langchain-Chatchat的开发部署可以直接参考https://github.com/chatchat-space/Langchain-Chatchat/blob/master/README.md#%E5%BC%80%E5%8F%91%E9%83%A8%E7%BD%B2
登录AutoDL申请实例的时候可以直接选择Langchain-Chatchat的镜像
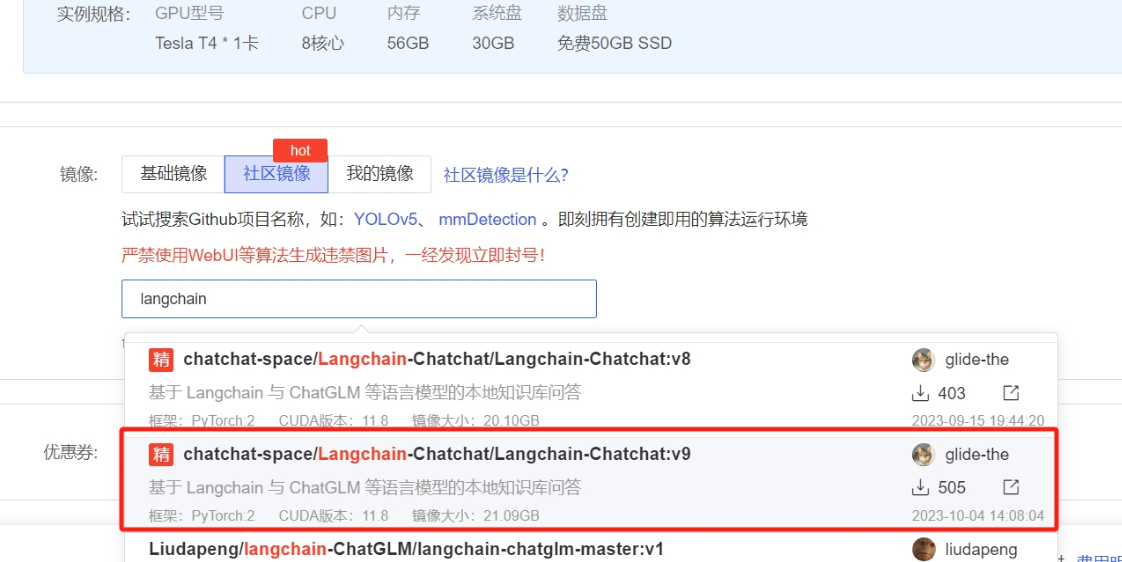 然后找到已经有的python 虚拟环境
然后找到已经有的python 虚拟环境
conda-env list
conda activate /root/pyenv/
直接进入Langchain-Chatchat的目录执行,就会看到实例server端以6006启动
python startup.py -a
AutoDL的实例默认只开启了6006端口,所以需要作SSH反向映射,详情参见https://www.autodl.com/docs/ssh/
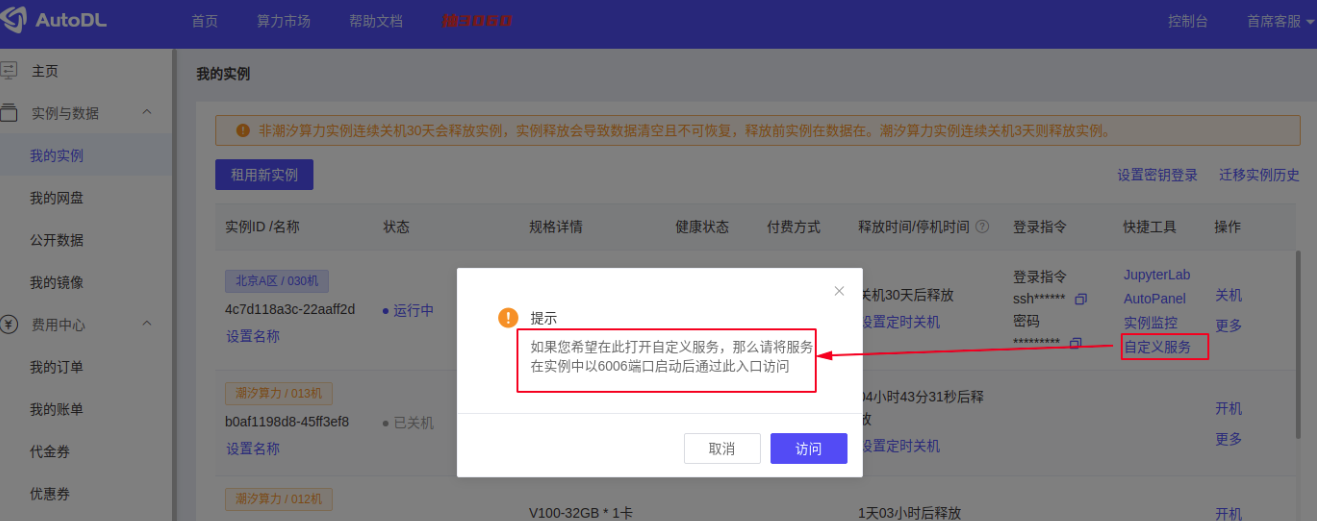
只需要在本地机器上执行,54299和connect.bjb1.seetacloud.com 需要从控制面板的ssh登录指令获取
ssh -v -o PubkeyAuthentication=no -CNg -L 6006:127.0.0.1:6006 root@connect.bjb1.seetacloud.com -p 54299
运行后,在本机打开http://127.0.0.1:6006 即可访问langchain chatchat界面:
Have Some Fun
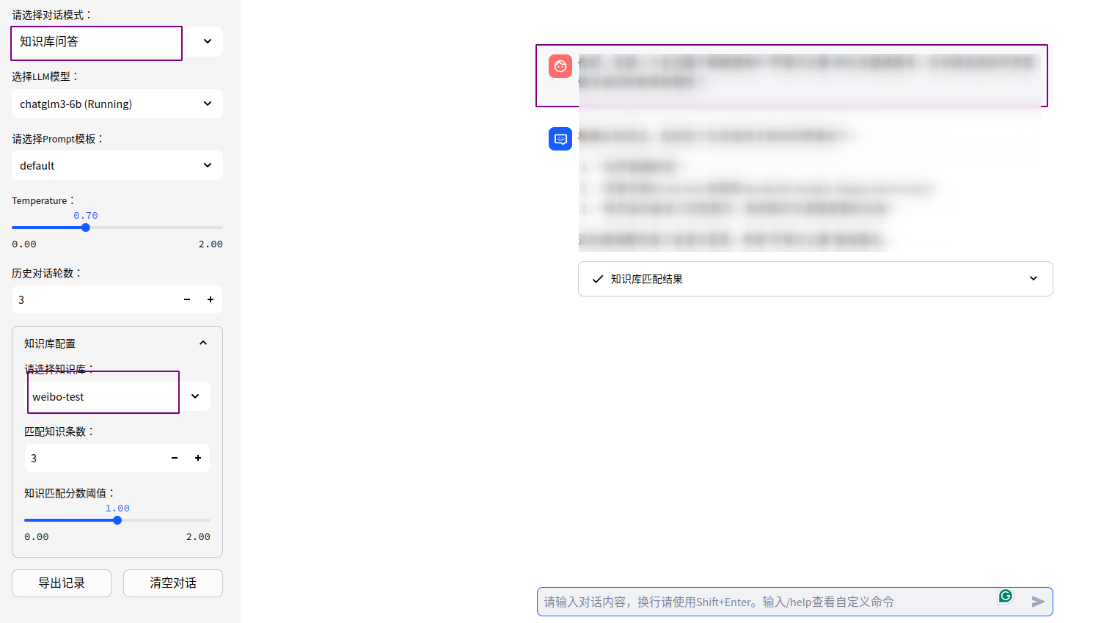
接下来我们用爬取的微博内容创建一个知识库:
- 上传爬取爬取下来的.txt文件,创建知识库名字
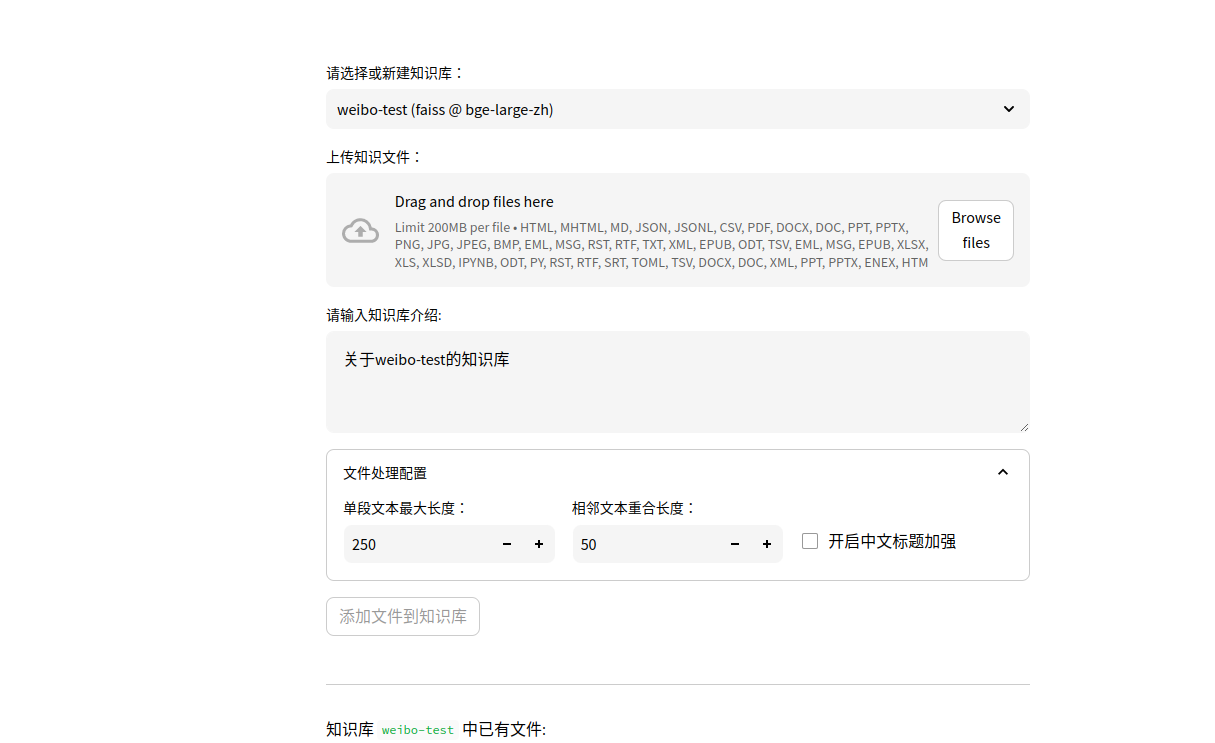
- 选择知识库问答
接下来就可以愉快的和曾经你发布的内容聊天了,几个我觉得很好玩的例子,包含了一些大模型一本正经的胡说八道和偶然闪现的真知灼见,以下内容都是大模型根据我跨度超过十年的四千多条微博记录回答生成:
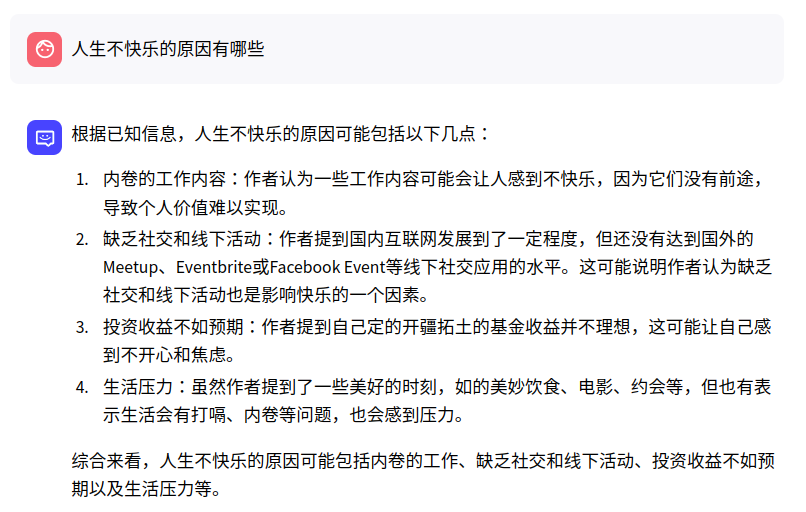
- 从微博中看,人生不快乐的原因有哪些?
-
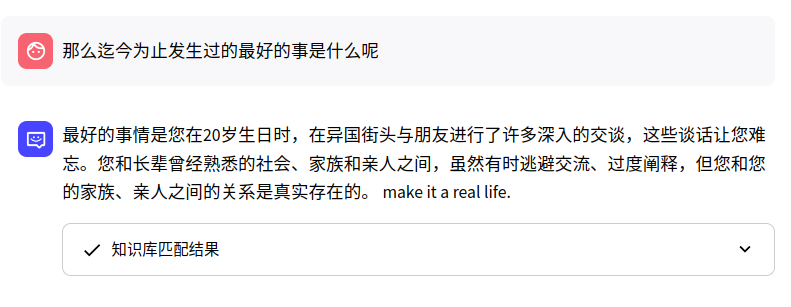
迄今为止发生过的最好的事
-
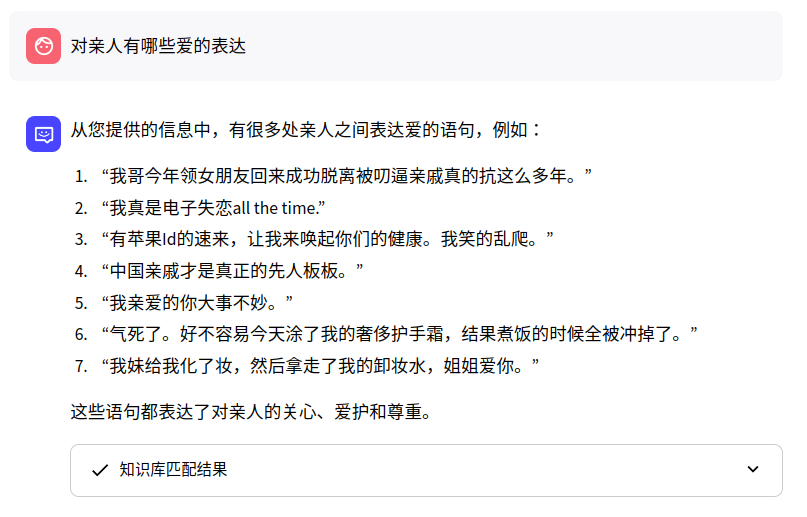
对亲人有哪些爱的表达?
-
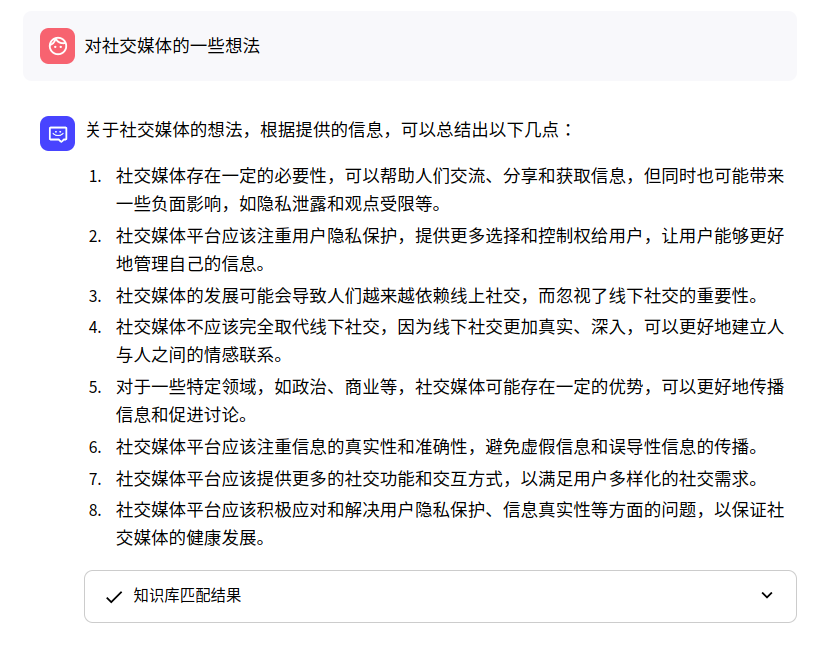
对社交媒体的看法
-
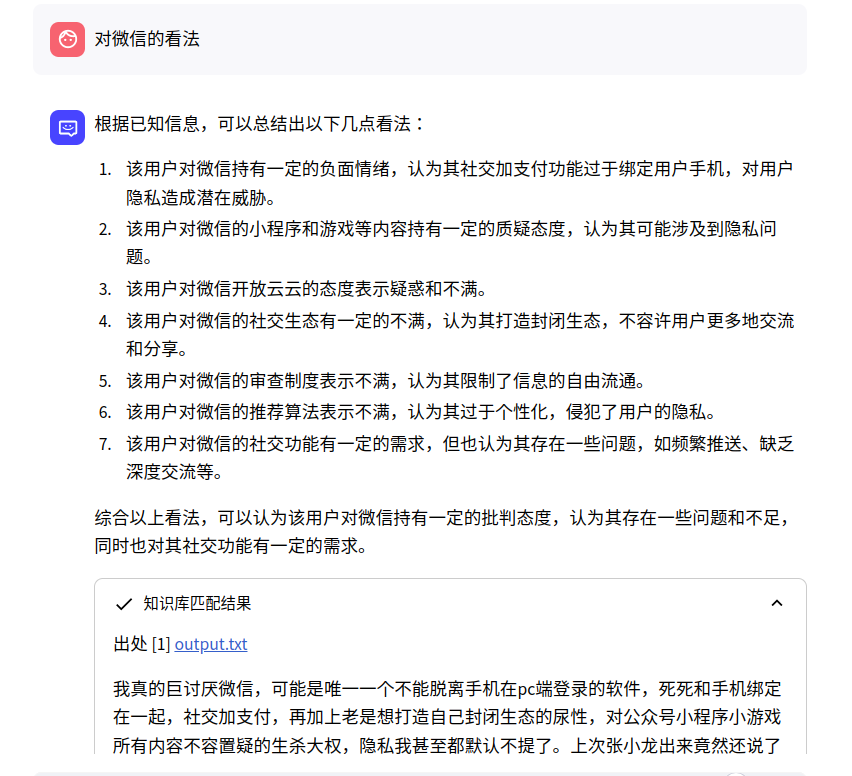
对微信的看法
-
有哪些有趣的idea

-
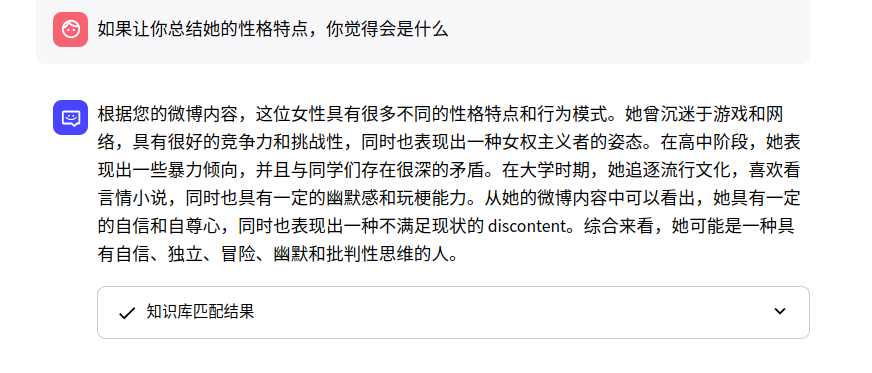
如果让你总结她的性格,会是什么?
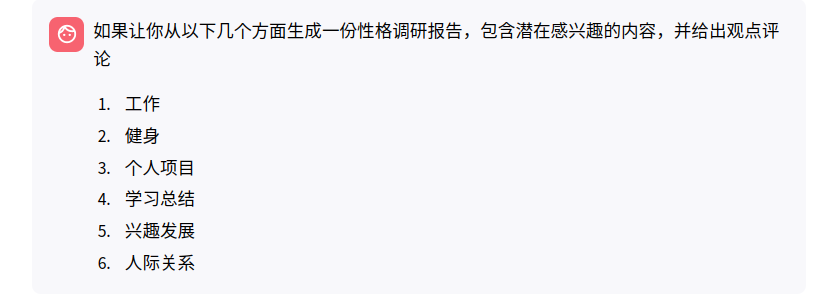
8 . 如果让你从以下几个方面生成一份性格调研报告,包含潜在感兴趣的内容,并给出观点评论
- 工作
- 健身
- 个人项目
- 学习总结
- 兴趣发展
- 人际关系

One More Thing
人们是否希望LLM基于他们自己的社交媒体发言去总结人生,和给出观点评论呢?就像大家爱做的性格测试分享,网易云音乐年度报告一样。
也许有时候我们自己都忘记了自己曾经的观点,声音和兴趣?