Sally Kang
why join the navy.
Mockingbird克隆声音初体验
[
最近一直在琢磨AI数字复活的事,比如以后亲人过世,是不是可以通过AI还原他们的声音和影像?就像今年商汤年会通过数字人的方式还原已故的汤晓鸥教授那样。B站也有很多用AI复活自己去世亲人的视频,甚至这已经变成了一个产业。
畅想一下,用AIGC比如chatGPT,根据特定的promote去扮演语言人格,早之前的deep fake, midjourney 或者现在最新的sora去生成某个人相关的视频,再用AI声音克隆去还原特定人的声音。
于是想玩一下声音克隆的东西,找到这个支持中文普通话的声音克隆项目,折腾了一晚上初体验了一下
项目地址:https://github.com/babysor/MockingBird
安装
我的电脑是ubuntu系统,所以参考官方wiki
环境安装如下
conda create -n sound python=3.9
conda activate sound
git clone https://github.com/babysor/MockingBird.git
cd MockingBird
pip install -r requirements.txt
pip install webrtcvad-wheels
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
由于科学上网,我本地的终端都走了代理,执行到pip install -r requirements.txt 时发现monotonic-align 找不到,开始以为是镜像源的问题,后来解决方法如下:
找到requirements.txt文件并打开。
在文件中查找并定位到包含"monotonic-align==0.0.3"的行。
删除"==0.0.3"部分,仅保留文本"monotonic-align"。
保存当前文档并关闭。
开始使用
准备音频
MockingBIrd默认只支持wav格式的语音,我使用的是苹果手机语音备忘录默认是m4a,随便在网上找个m4a to wav的转换网站

下载模型
官网提供的模型可以直接用main分支的第一个模型百度云链接已经失效,而剩下三个都需要切换到v0.0.1分支使用
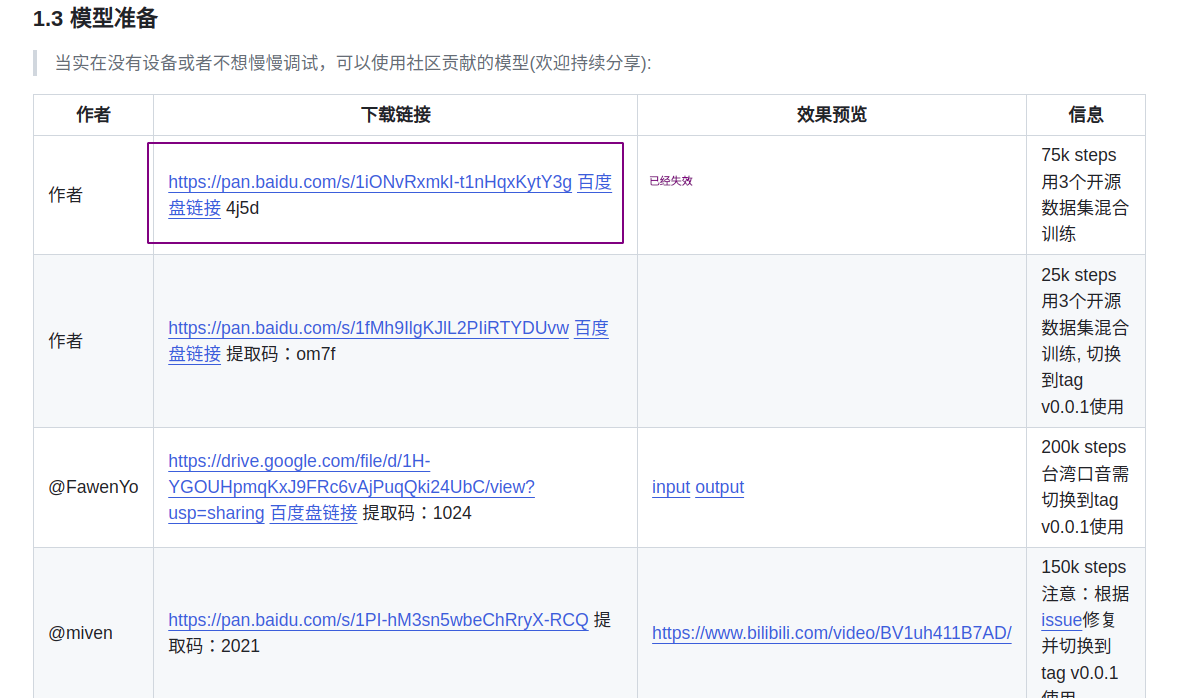
运行踩坑
如果有了synthesizer的pt模型,可以直接执行python web.py 或者python demo_toolbox.py 测试克隆声音而不需要重头训练
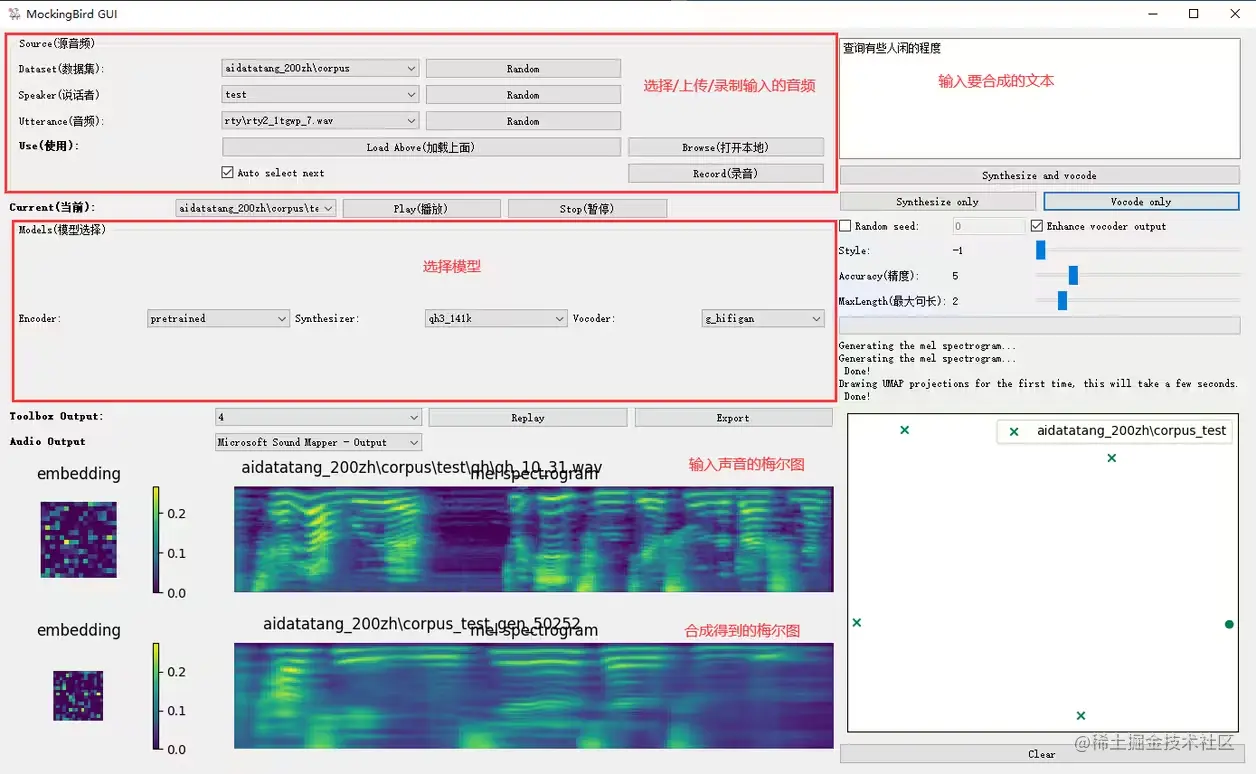
跑起来过程中可能有一些python库版本不兼容的错,一般是有什么错google什么,遇到一个解决一个,这里不再赘述。记录一下几个印象深刻的坑
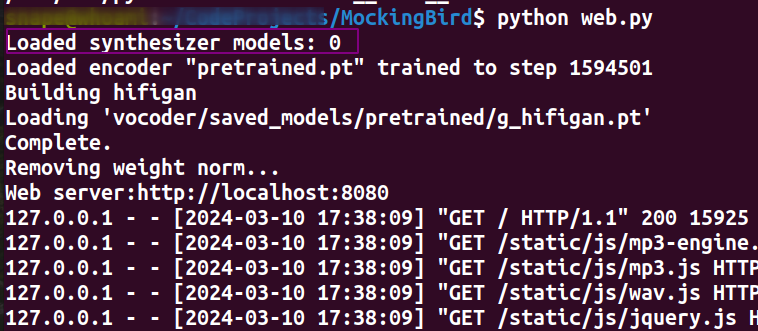
关于代码分支
值得一提的是如果你使用的v0.0.1的代码的话,会发现按照作者wiki里的文件结构没加载到synthesizer的pt模型

查看源码会发现,因为v0.0.1的代码默认是从synthesizer/saved_models/*.pt 下加载synthesizer模型的,而不是data/ckpt/synthesizer/*.pt
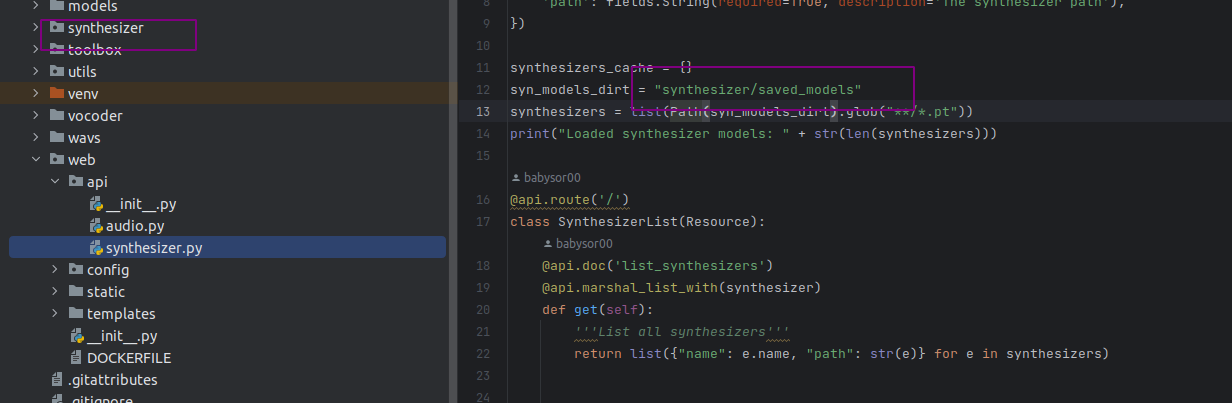
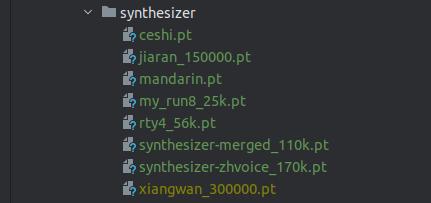
也就是说运行后三个官方wiki中提供的模型的话,你需要把pt文件都放到synthesizer/saved_models/
synthesizer的pt模型
试了试官方wiki中基于v0.0.1的几个模型,效果都非常的惊悚
这是原音
/audio/miao2.wav
这是鬼叫。。。
/audio/temp_result.wav
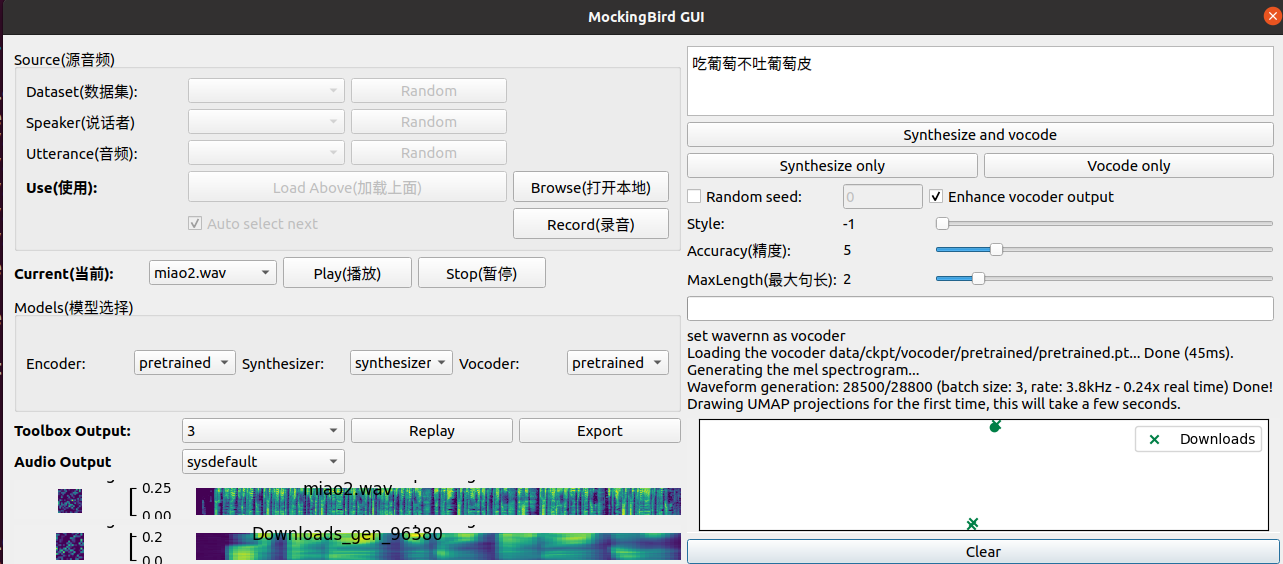
最后从网上搜罗到的模型测试,发现效果最好的还是synthesizer-merged_110k.pt
/audio/miao-test-1.wav
最后分享收集到的模型共大家把玩
https://drive.google.com/file/d/1uaki-yu-W-zMxTbJEWyynx-o8ksz5ZZU/view?usp=sharing